Less is More: When Agents Learn Not Because But Despite My Doings
A humbling story of how debugging led to a massive simplification that worked twice as well. Yes, RL is complicated.

Research Engineer @RLWRLD with Cognitive Neuroscience expertise
I work in robotics, developing software to teach robots. I also train gaming agents as a hobby, where the principles are similar and iteration is much faster. Many aspects of cognitive neuroscience training seem to transfer - designing evaluation tasks is similar, perception and action “networks” are comparable, and both involve extensive debugging.
During my PhD and postdoc, I used web-based cognitive tasks, brain imaging, eye-tracking, and machine learning to study human decision-making. For example, I developed The Choose-And-Solve Task to show how some individuals with math anxiety choose to avoid math and published my work in Science Advances (Choe et al., 2019).
See my Google Scholar page for other cognition works.
A humbling story of how debugging led to a massive simplification that worked twice as well. Yes, RL is complicated.
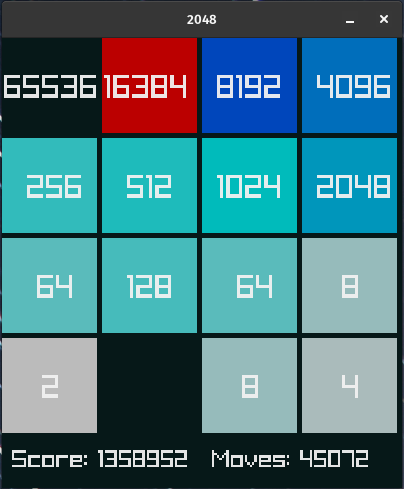
Training gaming agents that beat massive search-based solutions on 2048 using a 15MB policy, and discovering that bugs can be features in Tetris.
I'm living this, questioning what I thought was my expertise. AI models provide internet-scale possibilities, and motivated humans can crystallize one thread with their own preference and taste.

Simple and faster Perpetual Humanoid Control with Pufferlib
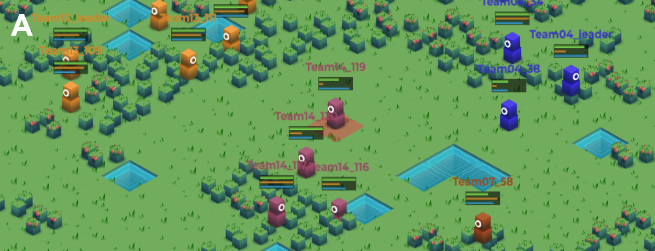
Generalist agent for Neural MMO games. Team battle, race to center, king of the hill, and sandwich modes.
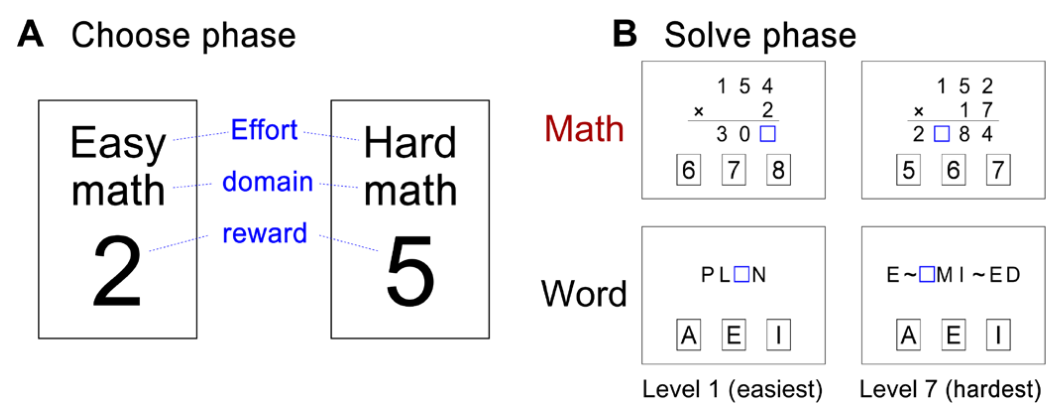
Effort decision-making task for measuring math avoidance. Published in Science Advances.
Tutorials for using jsPsych experiments with Qualtrics surveys.
Hosted on GitHub Pages — Theme by orderedlist,
page template forked from evanca.
Photo by Erielle Bakkum.