How the modern data stack is reshaping data engineering
https://preset.io/blog/reshaping-data-engineering/
Major trends affecting data engineers
In this post, I’m going to highlight the major trends in the modern data ecosystem and how they are affecting the data engineering role. Note that the goal here is to go wide and shallow and cover a lot of trends at a super high level before diving deeper into each trend separately in future blog posts.
Here are the trends I’m looking to cover:
- Data infrastructure as a service
- Data integration services
- Mountains of Templated SQL and YAML
- ELT > ETL
- The rise of the analytics engineer
- Data literacy and specialization on the rise
- Computation Frameworks
- Accessibility
- Democratization of the analytics process
- Erosion of the semantic layer in BI
- Decentralized governance
- Every product is becoming a data product
Modern data engineering teams are increasingly involved in selecting tools, integrating them, and keeping costs in check.
More generally speaking, I’d strongly advocate teams who are managing custom data integration scripts should treat those scripts as technical debt and actively migrate away from custom solutions and towards hosted solutions.
A clear trend is developing around applying some of the devops learning to data and creating a new set of roles and functions around “dataops”. We’re also seeing all sorts of tooling emerge around dataops, data observability, data quality, metadata management.
Rise of the Analytics Engineer
It’s been amazing to see analysts perfect their SQL and learn tools like git and jinja, but what does that mean for data engineers?
There’s something interesting here about orientation of the role. Specifically, I mean whether the role is:
- primarily vertically aligned (as in supporting a specific product vertical or team) or
- primarily horizontally aligned (as in building things that support a variety of teams and functions).
Assuming that the analytics engineer is primarily vertically-minded, this will enable the data engineer to focus more on horizontally-aligned initiatives. If the data engineers in an organization are excited to operate at a more foundational layer supporting analyst engineers, this brings new functions and responsibilities:
- owning core datasets: as analytics engineers cover more specific subject areas, data engineers may cover the mission-critical datasets that are heavily shared across teams
- data modeling: define and refine best practices around modeling data
- coding standards: define and defend naming conventions, coding conventions, and testing standards.
- abstractions: create and manage reusable components in the form of jinja macros libraries and computation frameworks
- metadata management: data assets documentation, discoverability, metadata integration, etc
- data operations: SLAs, data warehouse cost management, data quality monitoring, anomaly detection, and garbage collecting unused resources
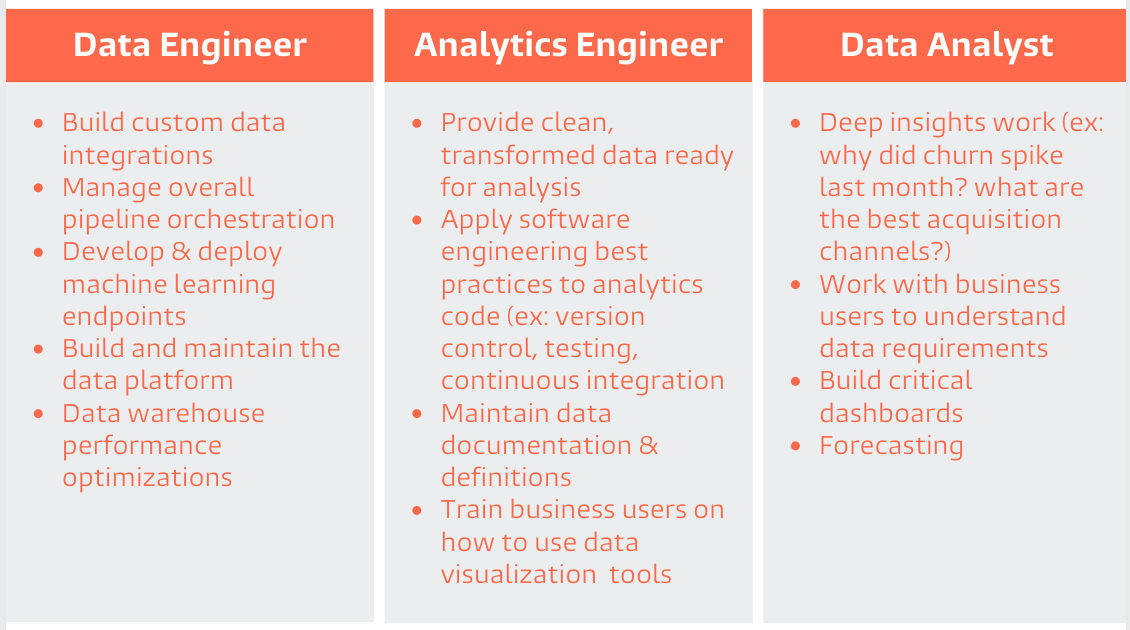
Here’s a helpful diagram from Claire Carroll’s blog post on the dbt Labs website:
Claire’s categorization is enlightening, though my mental model for it is probably better expressed as a venn diagram, where analytics engineering exists where the 2 established roles overlap with an emerging role in this middle section.
Another way to think about it is by relating it to the frontend, backend, and fullstack flavors of web development. There’s a spectrum with certain individuals covering different ranges and depth in different areas (T-shaped individuals!). Increasingly we hear conversations about where individuals fit on that spectrum, and job descriptions are more clear about the area or range they’re targeting.
Every product is becoming a data product
Moving forward, creating embedded data products is going to become much, much easier. Whether you call it headless BI or productized analytics, I’m excited for the future where tools like Superset will make it easier for teams to rapidly build and iterate on customer facing data products.