Less is More: When Agents Learn Not Because But Despite My Doings
Last month, I wrote about how curriculum learning helped me train a 2048 agent that reaches the 65k tile. That agent achieved a 14.75% rate of reaching 65k with many built-in heuristics to encourage the snake-pattern (keeping the highest tile in the corner with tiles arranged in a descending zigzag), and endgame-only training environments that capitalized on it.
This is a humbling story of how debugging led to a massive simplification that worked twice as well. Yes, RL is complicated.
The Bug That Caused a Panic
The 2048 environment had a subtle bug: terminal signals (dones) weren’t being returned correctly. This mattered because 2048 was being prepared for PufferLib’s RL algorithm benchmarking. When I fixed the bug (a one-liner) and retrained… learning slowed down and agents no longer reached 65k. Oh crap.
All those carefully tuned heuristics, the monotonicity bonuses and especially the snake rewards, had mysteriously been overfitting on this bug and seed 42. Probably that combination created favorable early conditions that led to the snake state. When the bug was gone, this path disappeared too.
The snake pattern was not a naturally arising strategy. It needed luck and complex nudges: rewards for putting the highest tile in the top left, rewards for placing tiles in decreasing order, and bonuses for forming the snake shape. Without the bug, much larger rewards were needed to entice agents toward the snake pattern, but then these interfered with learning to merge tiles.
A sign of this brittle path: I was only able to reach 65k 3 out of 10 times before. But I was so happy and exhausted to even achieve the 65k tile, so I took a break from 2048.
Inspiration from David Rubinstein
While I was taking a break, David Rubinstein (check out his awesome work on solving Pokemon with RL here) had been simplifying the 2048 observation space and network. He didn’t like the complex obs and heuristics so much, so he spent his weekends to make his point. His approach: no elaborate one-hot observations, just the grid with tile values, then use value and position embedding networks to encode the grid. No heuristic rewards, no complex curriculum. And he showed this simple setup could reach 65k.
His results made me think that the main reason I achieved the 65k tile was the capable network I ended up using. And maybe when the network is capable enough, it can just learn with fewer heuristics? I had ended up where I was because I started from a less capable network, and by adding heuristics, I could see gains. However, agents might have succeeded despite the heuristics, not because of them.
Changes Made
Well, I needed 2048 to work again. I also did not like the complex obs and complex rewards. It was an excellent opportunity to make it clean, so I started simplifying all I could.
Observation & Network: Adopted David’s approach. Before: 16 positions × 17 tile values as one-hot vectors + a one-hot indicator for snake pattern match (272 + 1 features). After: just 16 grid values with learned embeddings.
Heuristic Rewards: Removed corner placement and monotonicity rewards for top/left -> bottom/right sorting and snake pattern bonuses entirely.
Curriculum: Removed endgame-only environments (they relied on snake patterns). Simplified scaffolding: previously it placed high tiles in the top-left in sorted order to help agents build toward the snake pattern. With snake rewards gone, this was too biased, so now it places up to two large tiles randomly. A planned sweep on the proportion of scaffolding episodes will show how useful it actually is.
The Key Breakthrough, Merge Reward Scaling: The reward should reflect the actual difficulty. Reaching the 32k tile takes ~16,000 moves; reaching the 1024 tile takes ~500 moves. But previously, merge rewards scaled linearly with exponent, so merging 32k tiles gave only 50% more reward than 1024 tiles. Not nearly enough signal for the critical merges. I changed to power-1.5 scaling plus a small base. Even power-1.5 doesn’t fully match the difficulty curve, but it’s much better than linear (from g2048.h):
#define MERGE_BASE_REWARD 0.05f
#define MERGE_REWARD_SCALE 0.03f
// Pow 1.5 lookup table for tiles 128+
static const float pow15_table[12] = {
0.0f, 1.0f, 2.83f, 5.20f, 8.0f, 11.18f, 14.70f, 18.52f, 22.63f, 27.0f, 31.62f, 36.48f,
};
if (row[i] <= 6) {
// Small fixed reward for tiles under 128
*reward += MERGE_BASE_REWARD;
} else {
*reward += MERGE_BASE_REWARD + pow15_table[row[i] - 6] * MERGE_REWARD_SCALE;
}
This performed much better. It provided a cleaner and stronger incentive for merges, much better aligned with the goal of reaching higher tiles.
The 3 Simple Reward Components: The simplified reward system consists of just three components. The invalid move and game over penalties were already there; only the merge reward scaling was tweaked:
- Merge reward (positive): Power-1.5 scaling as shown above, rewarding tile merges with emphasis on higher tiles
- Invalid move penalty (negative): A small penalty when the agent attempts a move that doesn’t change the board state
- Game over penalty (negative): A penalty when the game ends, encouraging the agent to keep the game going longer
The Results
| Metric | Original | Simplified |
|---|---|---|
| Lines of code | ~700 | ~500 |
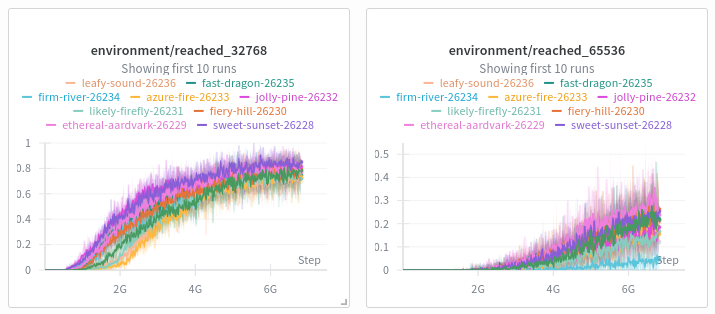
| 32k tile rate | 71.22% | 84.88% |
| 65k tile rate | 14.75% | 33.96% |
| Observation features | 18 per cell | 1 per cell |
| Reward components | 6+ with complex heuristics | 3 simple components |
Also observed 65k in 10 out of 10 runs with different seeds. Ready for benchmarking!
Lessons Learned
The Bitter Lesson, again. Heuristics might help short-term, but capable agents will just learn from diverse experience. The intuitions I had built up were partly wrong. The snake pattern was easier for me to understand, but it limited performance. Agents trained with simple rewards perform complex tricks I never would have thought of, and they do much better. See for yourself here.
Don’t overestimate intuition, don’t underestimate computation.
Well-designed rewards still matter. The power-1.5 merge scaling was crucial. After all, the R in RL is reinforcement for what matters.
Try It
Watch the agents play: Simplified 2048, Snake Pattern 2048
Code: github.com/kywch/PufferLib/tree/simple-2048
PR #474 was merged into PufferLib 4.0, which is being actively developed now.